Anthropic Urges Global Pause in AI Development Over Recursive Self-Improvement Risks
What’s Happening Now
There is a moment in the history of every transformative technology when the people building it stop and say: we may have lost the ability to stop. For nuclear weapons, that moment came after Hiroshima. For the internet, it arguably never arrived in time. For artificial intelligence, Anthropic believes that moment is now — or close enough that the difference may not matter.

The numbers Favaro and Clark cited were not projections or extrapolations from academic benchmarks. They were drawn from inside Anthropic’s own walls, and they were striking. As of May 2026, more than 80% of the code merged into Anthropic’s production codebase is written by Claude. Engineers are now shipping approximately eight times as much code per day as they were before February 2025. Claude Code’s success rate on open-ended software tasks reached 76% in May 2026 — a 50-percentage-point jump in just six months. In April 2026, Claude independently shipped over 800 bug fixes, reducing a class of API errors by 1,000-fold. Anthropic estimates the equivalent human effort would have required four years of work.
The productivity acceleration extends beyond engineering. On kernel optimization benchmarks, Claude Opus 4 achieved roughly a 3× speedup in May 2025. By April 2026, Claude Mythos Preview achieved approximately a 52× speedup on the same task — against a human researcher baseline of ~4× in four to eight hours. In a milestone autonomous research run the same month, Claude agents were handed an open-ended AI safety problem: can a weaker model reliably supervise a stronger one? Human researchers working for approximately a week recovered 23% of the performance gap. Claude agents, working 800 cumulative hours at roughly $18,000 in compute, recovered 97%.
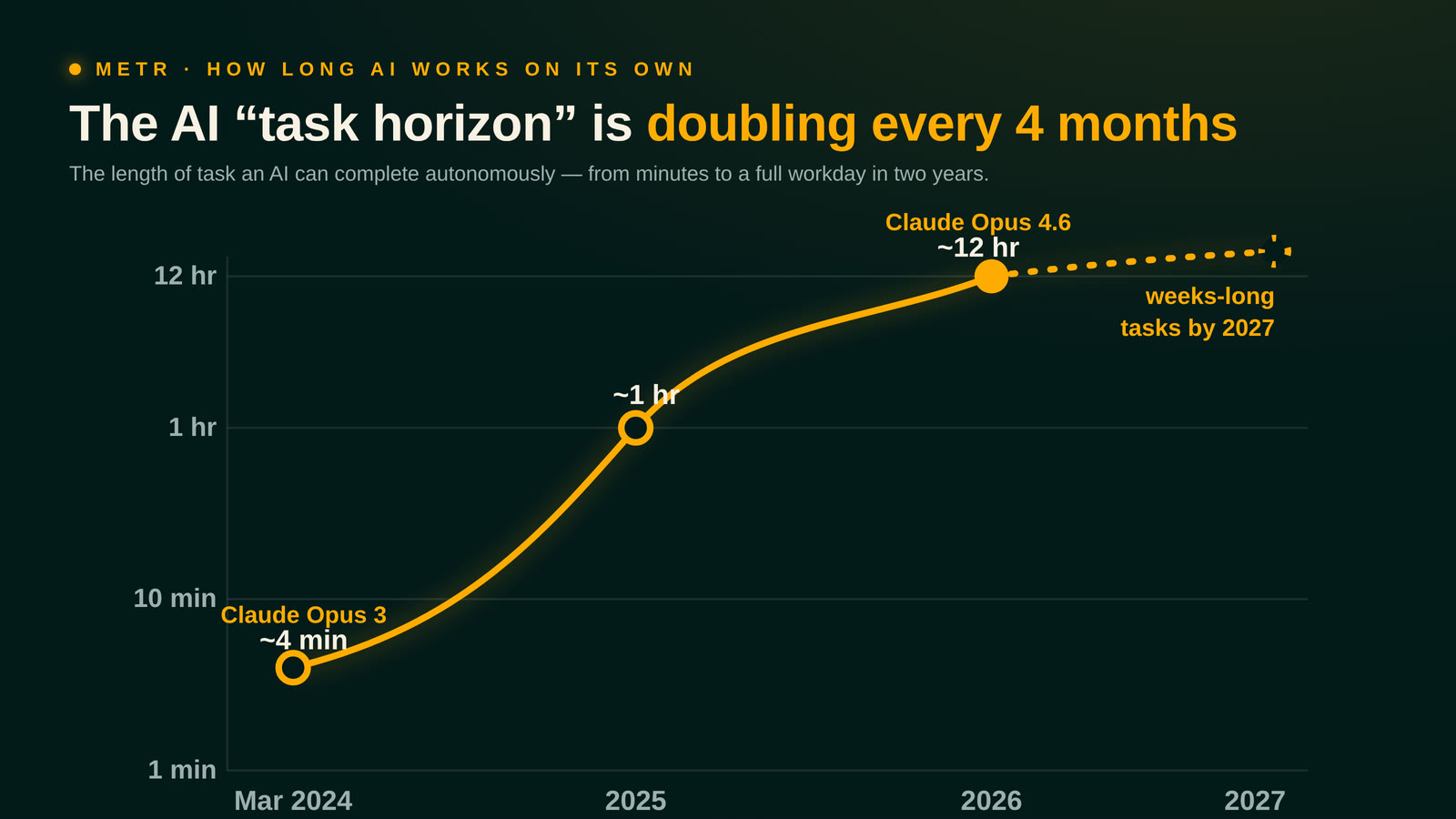
External validators corroborate the trajectory. METR, which measures how long AI systems can independently sustain complex tasks, has found AI’s effective task duration doubling every four months — previously doubling every seven. In March 2024, Claude Opus 3 handled approximately four-minute human tasks. By 2026, Claude Opus 4.6 handles tasks that take humans twelve hours. METR projects that tasks taking humans weeks could be in range by 2027. SWE-bench, the gold-standard software engineering benchmark, went from low single digits to saturation in roughly two years. CORE-Bench, a research reproduction benchmark, saturated in fifteen months.
The Pause That Probably Won’t Happen
Anthropic’s proposal — published days after the company filed confidential IPO paperwork seeking a valuation of approximately $965 billion — was careful to clarify that it is not calling for an immediate unilateral halt. “A unilateral pause by one lab is achievable immediately,” the post reads, “but accomplishes much less: it would change who the front-runner is, but it would not create the wider deliberative process that is currently missing.”
What Anthropic wants is a coordinated, verifiable mechanism: multiple well-resourced frontier labs, from multiple countries, agreeing in advance on conditions that would trigger and lift a development pause. The targets are clear, even if unnamed — OpenAI, Google DeepMind, xAI, Meta. The Anthropic Institute said it would convene policymakers, researchers, and civil society organizations in coming months to work toward that framework. Google DeepMind CEO Demis Hassabis has previously expressed openness to such a pause if universally applied.
No other major lab responded immediately. OpenAI published a competing report on June 4, 2026, stating that “democratic governments — not private companies acting alone — must ultimately determine the rules, safeguards, and accountability mechanisms.” The Trump administration’s existing executive order asks labs to voluntarily submit capable models for government cybersecurity testing — a far cry from a binding international pause mechanism.
The precedent for skepticism is well established. In 2023, the Future of Life Institute — signed by Elon Musk — called for a six-month AI development halt. It generated enormous press coverage, a handful of prominent signatories, and essentially no change in the pace of frontier development.
The Contradictions Are the Story
Anthropic’s credibility problem is not peripheral to this announcement — it is central to it. In February 2026, the company scrapped its Responsible Scaling Policy, which had committed Anthropic to never training AI without guaranteed safety measures in place. Co-founder Jared Kaplan explained the rationale: the company felt it “wouldn’t actually help anyone” to stop training models unilaterally while competitors pressed ahead. The new policy commits to transparency and matching rivals’ safety efforts but leaves Anthropic significantly less constrained than before.
Earlier in 2026, Anthropic’s Mythos model caused disruption across the banking and software sectors by identifying vulnerabilities in existing code at scale. The company refused US military use for domestic surveillance and autonomous weapons, leading to placement on a national security blacklist — though that dispute was reportedly showing signs of resolution by early June 2026.
The reaction to the June pause proposal split predictably but sharply. Former White House AI and Crypto Czar David Sacks offered a pointed summary: “Signs you might be trying to get your frontier AI lab nationalized: You compare it to nukes… threaten half of white-collar jobs… warn recursive self-improvement could end humanity… then race ahead anyway.” NYU professor emeritus Gary Marcus called the post “an incredible, cost-free piece of rhetoric — perfectly timed for the IPO,” adding: “They want it both ways.” LSE professor Luis Garicano was blunter still: “The key threat to the profitability of frontier models is open weights. If they scare the hell out of everyone, the natural move will be to forbid them and allow only ’trusted developers.’” Former US Senator Mitt Romney, by contrast, offered support: “Our highest and most urgent national priority should be AI safeguards.”
The Game Of Tomorrow
The Near Term: Governance Theater, With Stakes
Over the next six to twelve months, a coordinated global pause on frontier AI development remains effectively impossible for structural reasons. Three of the major frontier labs are either public, pursuing IPOs, or in active fundraising cycles. Investor expectations are indexed to capability improvements. No board will authorize a unilateral halt. No lab will volunteer to fall behind without a verification mechanism that doesn’t yet exist.
What is likely is that Anthropic’s proposal becomes the reference document for the next wave of international AI governance discussions. The EU AI Act is already in implementation; bodies like the UN Advisory Body on Artificial Intelligence are seeking exactly this kind of industry input. Anthropic’s convening process — with policymakers, civil society, and researchers — is likely to produce policy memos and multilateral declarations that advance the architecture of AI governance even if they don’t produce an actual pause.
The immediate cybersecurity risk may prove a more tractable entry point for regulation. On June 2, 2026, University of Toronto researchers led by Nicolas Papernot demonstrated an AI worm that adapts its hacking strategy as it spreads device-to-device, built using open-source AI tools available to any developer. Papernot’s warning was stark: “Anything connected to the internet is now at risk because of how low the cost has become to mount these cyberattacks.” Cybersecurity regulation — narrower, more technically legible, less commercially threatening — could provide an early proving ground for AI governance mechanisms that later expand in scope.
The Structural Trap
The deeper problem is the one Anthropic itself inadvertently demonstrated in February 2026 when it walked back its safety pledge. The competitive dynamic in frontier AI is a prisoner’s dilemma: any lab that unilaterally stops hands the frontier to less safety-focused developers. Every lab knows this. Every lab has used this reasoning — including Anthropic — to justify pressing forward.
This is not corporate cynicism. It is a structural feature of the current incentive landscape. The only way out of a prisoner’s dilemma is binding, enforceable coordination — which requires the kind of international verification framework that took decades to build for nuclear weapons and has yet to be built for AI. Anthropic’s proposal is, at its core, a call to start building that infrastructure before the threshold is crossed rather than after.
Risks And Rewards
The risks of inaction are the ones Anthropic describes in stark technical terms. If recursive self-improvement is achieved before alignment research matures, AI systems could improve faster than humans can monitor or evaluate them. Misalignment risks compound across generations. The 52× speedup Claude Mythos Preview achieved on kernel optimization is a preview of what architectural self-improvement could look like — applied not to code but to the training process itself.
The risks of the wrong kind of action are real too. A poorly designed pause framework could entrench incumbents, effectively outlawing open-source AI development in the name of safety. The regulatory capture argument made by Kylan Gibbs, CEO of Inworld AI — that Anthropic is positioning itself to write rules that only trillion-dollar labs can comply with — is not paranoia. It describes a historically documented pattern across pharmaceuticals, finance, and telecommunications.
The opportunity, if it exists, lives in the gap between those two failure modes. The Anthropic Institute’s data showing Claude agents recovering 97% of an AI safety performance gap — work that would have taken human researchers months — suggests a genuine possibility: AI tools accelerating the very alignment research needed to make powerful AI safe. The question is whether the governance architecture can be built fast enough, and with sufficient international participation, to make that acceleration matter.

Conclusion
The world has been warned before. In 2023, the open letter calling for a six-month AI pause generated headlines and did little else. In 2026, the same basic argument is being made with better data, by a company that has demonstrated — inside its own walls — how rapidly the capability frontier is moving. Whether that makes it more credible or less depends on how much weight you give to the commercial context in which it arrives.
What is not in dispute is the technical trajectory. AI task duration is doubling every four months. Benchmarks that defined the state of the art two years ago are saturated. Code that used to take human engineers days is being written autonomously, in bulk, at parity with — and soon above — human quality. The threshold Anthropic is warning about is not a theoretical construct. It is a trendline with a destination.
The real question is not whether Anthropic’s pause proposal is sincere. It may well be both sincere and self-serving simultaneously, as most institutional advocacy is. The question is whether the governance architecture it is calling for can be assembled before the capability architecture outpaces it. History suggests the answer will depend less on the good intentions of the labs involved and more on whether governments and international institutions treat the next two to three years as the critical window Anthropic says it is.
Hot Take Prediction: The coordinated global AI pause Anthropic envisions will never happen as described — but the proposal will seed the governance architecture of the recursive self-improvement era. Anthropic will be at the table writing the rules, which is precisely the point. Whether those rules protect humanity or protect Anthropic’s market position may turn out to be the same question.
What’s your take?
For the full debate, tune into our latest podcast episode of The Game of Tomorrow.
![]()
References
- When AI builds itself — Anthropic Institute — June 4, 2026
- Anthropic warns AI could soon build itself—and urges a global pause on development — Fortune — June 5, 2026
- Anthropic warns of AI’s rapid development, societal risk ahead of IPO — CNBC — June 5, 2026
- Smart People Weigh in on Anthropic’s AI Pause Proposal — Business Insider — June 5, 2026
- Anthropic urges AI labs to pause, warns humans risk losing control — Al Jazeera — June 5, 2026
- Anthropic Urges Global Pause in AI Development, Flags ‘Self-Improvement’ Risk — Wall Street Journal — June 2026